Setting up a high availability environment
Service high availability is a key aspect of any organization and any piece of software must meet all the requirements necessary to achieve redundancy on all fronts. As an enterprise DXP, Jahia products aim at meeting the best standards in terms of SLA.
High availability is not only about a resilient service that can cope with hardware failure. It is also about maintenance operations that could require taking the service down. High availability is also about scaling to meet traffic spikes and gracefully serve all incoming requests, no matter how big they grow.
Jahia is able to meet the most rigorous standards in regards to all of these requirements and is successfully used every day by clients all around the world with SLAs up to 99.99%. This article explains the most important considerations to achieve high availability with Jahia.
Service redundancy
Services are pieces of software whose job is to perform a task, either alone, or along with other instances of the same service. This section goes through all services of Jahia's ecosystem and provides guidelines on how to make them highly available.
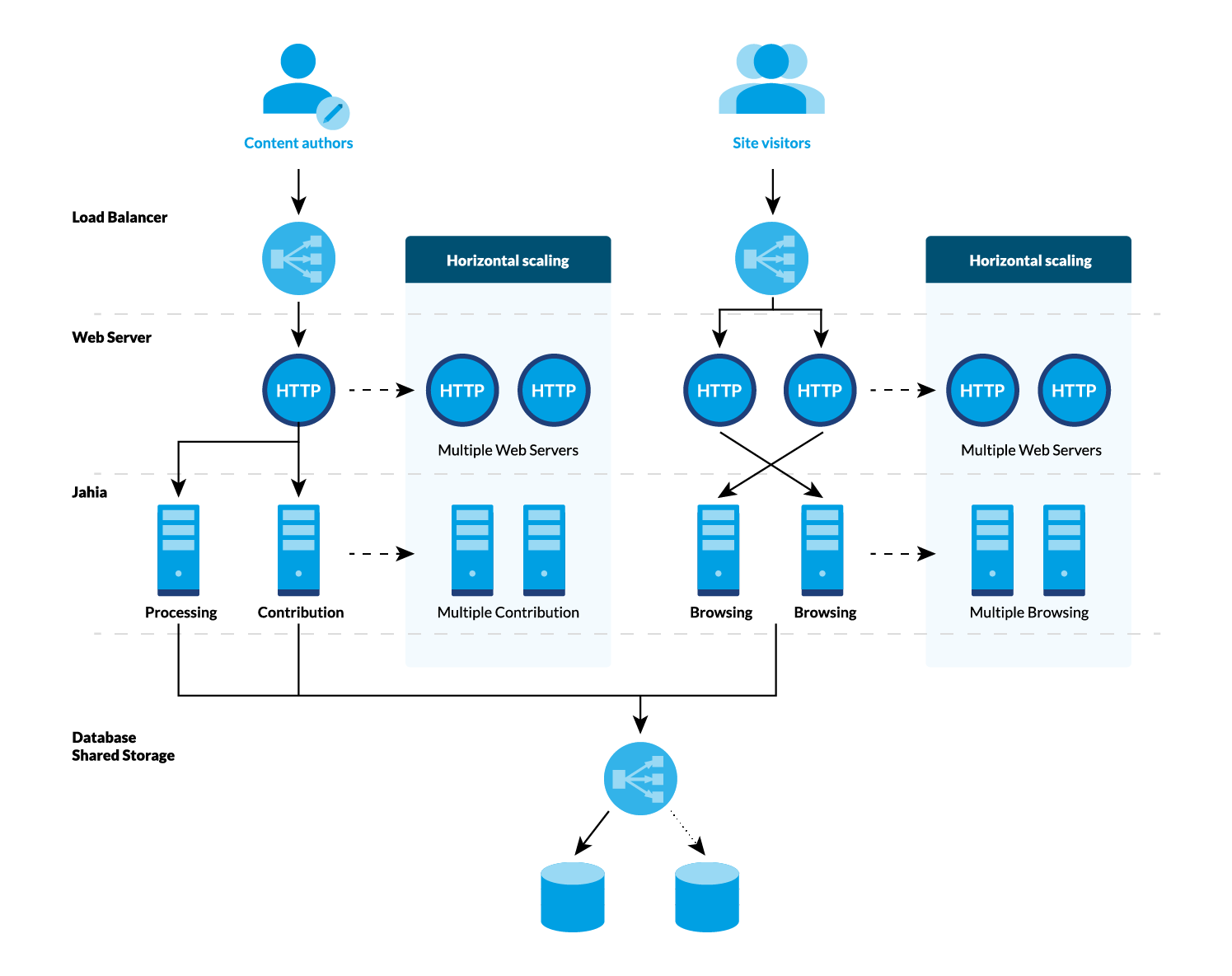
Load Balancing
Load balancers' job is to distribute traffic amongst web servers. Jahia can work with all types of load balancers, whether they are physical (F5, Cisco LB) virtual (Amazon ELB, Azure Traffic Manager) or software (nginx plus). Load balancers can work on a highly distributed and fault tolerant way and play a great role in the overall high availability of architecture, as the main entry point.
Finally, some load balancers can handle SSL termination with hardware decoding, which makes them extremely efficient at decoding HTTPs.
Web servers
Web servers play two major roles: route the various HTTP calls to the right application server, and create a layer of isolation between the internet and the application server. There are also important tasks that can be offloaded to web servers such as URL rewriting, but these are out of the scope of this documentation.

Several configurations might be considered, but the "n to n" is definitely our favorite for a number of reasons:
- Losing one web server won't make one Jahia server unreachable
- It allows sticky session at the web server level
Of course, web servers and application servers will not scale the same way, and it is not necessary to provide the same number of servers for either side of the architecture.
Application servers
Application servers are the components containing Jahia. Even though all Jahia instances are the same from an application standpoint, each of them can be configured separately in order to specialize them.
Processing node
There can be only one processing node on the whole architecture.
The processing node is not considered a sensitive part of the architecture since it performs background jobs that do not prevent serving content to site visitors:
- Module deployment
- New versions of the custom code will only be fully deployed once the processing node is online
- Content publication
- Content authors can still contribute content and request publication, but these publications will be queued until a processing server is online
- Jobs execution
- Cache purge, content history purge, version purge
While performing important tasks, the global architecture will not suffer from a processing node crash and visitor and content author requests will still be served without impact. In case of a processing node failure, it is however important to restart it to allow content publications and module deployment. All jobs are persisted in the database and resumed when the processing node goes online.
It is common to have the processing node also act as a contribution server on architectures without heavy content contribution activity.
Contribution servers
Contribution servers are servers where content authors will create and trigger content publication. These servers also offer administration interface for users, roles, module and other various component management.
In case content contribution is considered a sensitive activity on a platform and high availability needs to be achieved, it is required to provide at least two contribution servers.
Browsing servers
Browsing servers are servers dedicated to serving visitors HTTP requests. In a highly available configuration, it is mandatory to provision multiple browsing nodes. See Capacity Planning for information on the best way to size an architecture.
Most common architectures
Depending on the volume of contribution and visitor traffic reaching the platform, different architectures can be evaluated.

High availability on the browsing part of the architecture, not on the contribution
Even though Jahia can virtually run on any setup, including the one where a single server would act as a processing, contribution and browsing node, we tend to stay away from any setup where a server could be seen as a Single Point of Failure. For low throughput websites, the above architecture is the most commonly used.

High availability on the contribution and browsing parts of the architecture
Architectures with a high number of concurrent content contributors or when the contribution is seen as a critical activity need to have at least two contribution nodes. In this case, a 4-node architecture is advised.

High availability on all sides of the architecture and high traffic throughput capacity
For sites that serve hundreds or thousands of requests per seconds, the number of browsing nodes to be added to the architecture is not limited. Your account manager and customer solutions team can help you decide on the best course of action to come up with an adequate setup.
While it is important that Jahia can scale to serve dynamic and highly personalized pages and API calls, static content such as CSS, Javascript and images can be served by a Content Delivery Network (CND) if necessary.
Data redundancy
Sessions
Sessions being volatile data wiped at server restart, they are often neglected and only stored at the application server level. This is however not always the best choice, as sessions allow user authentication persistence and may also store valuable transient business data.

This setup is however non-optimal. One of the problems comes from the usage of sticky sessions, which make it impossible to shutdown an application server node without all the sessions associated with it. Any failure in the architecture would also disconnect all users that had sessions opened on the failed server.

Distributing sessions with hazelcast
Jahia provides out of the box support for distributing sessions across all application servers by using hazelcast, through the distributed-sessions module. Hazelcast ensures all session data is replicated on all servers, allowing a user to fallback on another server if the one he was using is failing.
When sessions are distributed with Hazelcast, application servers can be added and removed freely without impacting the site's visitors.
Virtual infrastructures involving auto-scaling, and Container as a Service platform frequently add and remove servers from an infrastructure to adapt to HTTP traffic volume. In this case, it is essential to provide session distribution and prevent any impact on visitor sessions.
Indexes
Jackrabbit uses the same technology as Elasticsearch in order to provide high performance and scalability on data: Lucene indexes stored locally to optimize read latency and perform CPU-intensive queries without overloading the database.

Jackrabbit indexes are stored locally with each Jahia instance
While storing indexes locally is the best option for high performance and the overall architecture scalability, it comes at a cost when scaling the architecture and adding new Jahia nodes. The newly added server needs to generate its own copy of the indexes before it can respond to HTTP requests that perform queries (explicit or implicit)
Fortunately, Jahia comes well equipped regarding Jackrabbit indexes management, and two easy alternatives can be put in place:

Copy existing indexes from another server. Indexes from Jahia servers that belong to the same cluster are all the same and can be copied at will.

Add the new server and let Jahia generate its indexes. It can take between 2 minutes and an hour depending on the size of the content of the platform
For auto-scaling environments, it is important to copy indexes across instances (or data volume, depending on the technology) in order to ensure a fast startup of newly summoned nodes.
Database and datastore
The database and the datastore store the persistent data of the platform and need to be highly available. While IaaS platforms make it easy with out-of-the-box multi-availability zone backends, databases installed on bare-metal servers will require more efforts to become highly available.
Database
Jahia supports the active-active (read/write) DB setup of MariaDB clusters with Galera. Other active-active setups are currently not supported.
Jahia supports MariaDB Galera clusters and allows load-balance read operations across the whole cluster. Write operations must be sent to the same MariaDB Galera instance to avoid cluster locks.
Two load balancing strategies are supported:
- Query load balancing using HAProxy where read operations are load balanced across the whole Galera cluster. Write operations are sent to only one Galera instance.
- Load balancing achieved by the MariaDB JDBC driver configured in 'sequential' mode (see About MariaDB Connector/J). The first MariaDB instance in the connection string will be used and no load balancing will occur. An automated switch to the next MariaDB instance will occur in case of a failure of the first one.
While the HAProxy setup allows for a better scalability, the JDBC driver option is simpler to configure. Your choice depends on the size of the project and projected number of connections.
The following example shows how HAProxy is used to connect a Jahia cluster to a MariaDB Galera cluster:

Installation resources
- When installing Jahia, you will need to select MariaDB 10.x as DBMS type, and then use the address of the HAProxy server as the database URL.
- MariaDB Galera cluster documentation: https://www.linode.com/docs/databases/mariadb/set-up-mariadb-clusters-with-galera-debian-and-ubuntu/
Please note that you will need to set the value ofmax_allowed_packetto 100M and thelog_bin_trust_function_creatorsto 1 for each MariaDB node. - HAProxy documentation: HAProxy
Datastore
While being optional, the datastore is a shared folder usually using NFS volumes or SAN storage. The datastore requires high availability at the storage level (RAID or replicated storages using dedicated solutions such as Netapp or out-of-the-box highly available IaaS storage).
Maintenance operations
Module deployment
The limited downtime module deployment procedure allows the deployment of custom code on a server-by-server basis.

The limited downtime procedure helps deploy custom code (modules) while serving HTTP traffic. It is necessary to remove servers from the load balancers when deploying custom code as it takes between 200ms to 2 seconds per module to be fully operational.
Jahia platform upgrade
Platform upgrading is a key aspect of a platform’s high availability. While it is essential to ensure that a platform stays up-to-date at all time (for a number of reasons ranging from security to performance improvements and getting the latest fancy features released in each version), platform upgrading may also involve service downtime.
Different strategies can be used to ensure a zero-downtime platform upgrade.
Rolling upgrade
A rolling upgrade is usually used in fully automated environments where infrastructure operations are made easy thanks to IT management tools such Chef, Puppet, Jenkins and Kubernetes. This strategy allows to use the existing servers and update them on a one-by-one basis while serving HTTP traffic with the remaining computation power.
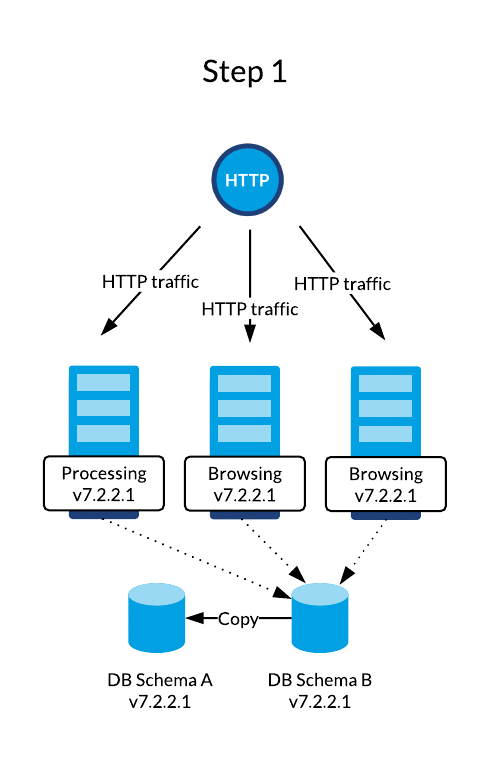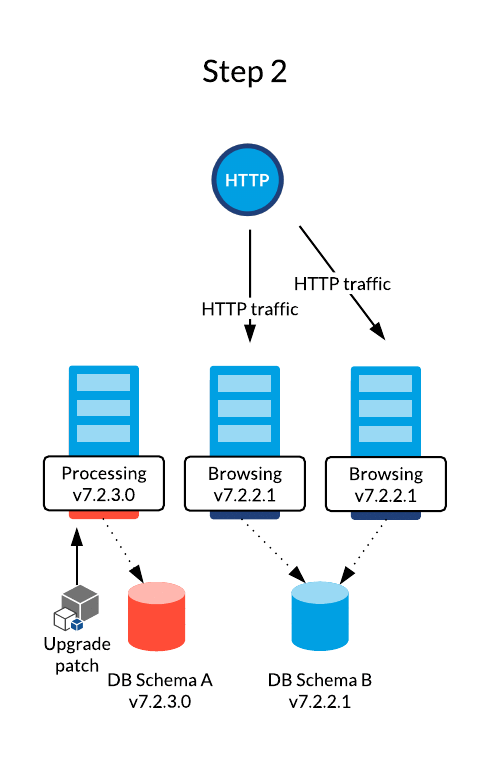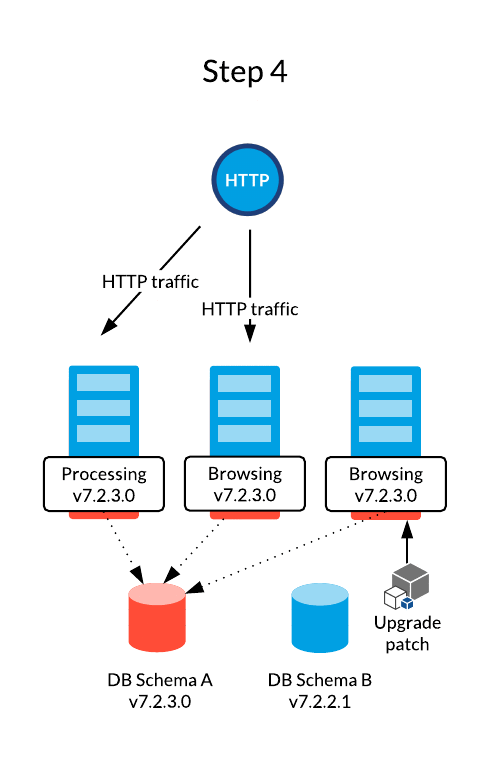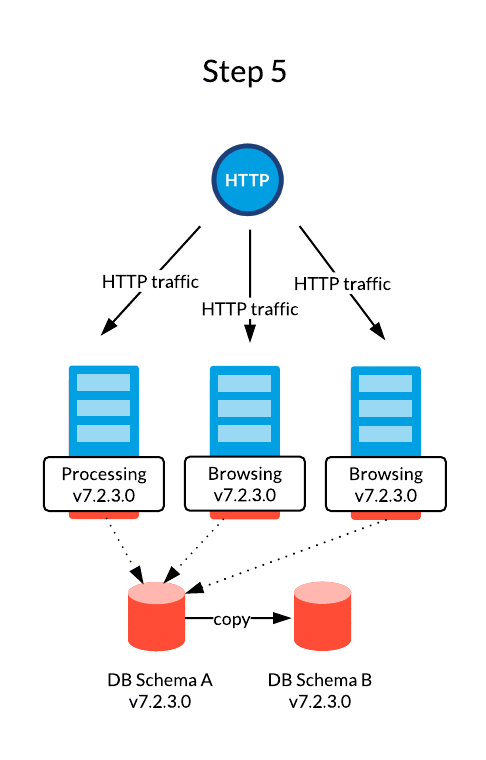
Jahia core’s upgrading mechanisms are designed to avoid impacting websites and features availability in any way. Hence, it is perfectly acceptable to serve traffic using two different versions at the same time. HTTP sessions can also be mutualized between both versions to preserve a unique execution context.
The Rolling Upgrade procedure's documentation is available here
Blue/Green upgrade
Blue/Green upgrade is easier to put in place compared to rolling upgrade, but it will also require more resources since it usually involves fully duplicating the primary environment. Please note that Blue / Green environments usually serve as failover environment when needed.

When an upgrade needs to be performed, it is first done on the Green environment. The traffic can then be switched to the Green environment, hence allowing the Blue environment to be upgraded as well.