Infrastructure capacity planning
What architecture to choose, when do I need to add more capacity to my infrastructures? This guide aims at answering these questions.
Capacity planning is often a trade off between multiple factors ranging from technical aspects (physical hardware capacity) to content lifecycle, code sharing and teamwork. It is important to consider all aspects of it before making a decision.
Technical considerations
The scalability of an architecture depends on a lot of factors, we won’t be able to take all of them into account in this document, but we can provide a baseline.
A mixed scenario with a lot of authoring and browsing activity demonstrates that each reasonably sized Jahia server is able to comfortably handle 2700 simultaneous visitors. Adding more nodes to a cluster pushes that figure easily.
However, this figure might be different in your environment:
- “Simultaneous visitors” is too vague:
- What is the “think time” (time between each action)?
- What is the user doing? Displaying content? Doing searches?
- How many pages is a user visiting per session?
- How many assets are we loading for each page? (number of pictures/CSS/Javascript files)
- Are we using a static asset cache (local cache or internet CDN?)
- How complex are the pages?
- How optimized is the code base?
- Is the user authenticated?
- Is the site personalized for the user?
- What is the physical configuration of each servers? (CPU/Memory/File system…)
This “2700 simultaneous visitors” per server needs to be adjusted based on the result of your performance tests.
Note that the total number of unique users and the number of simultaneous users connected to the platform are not necessarily correlated. 10M potential users with a very low frequency access (once a month) would generate less traffic than 10k users accessing the platform several times a day. For that reason, we tend to ignore the number of unique users accessing the platform and think of the number concurrent users during spikes. (see next section)
Traffic spikes
Architecture sizing needs to be done based on the “worst-case scenario” and not based on the average traffic. Determining when the traffic surge usually occurs is a good start. Is it everyday in the morning? Once a month a specific day? Answering that question is key.
User-specific blocks
A personalized user experience usually means more efforts to build a page for each visitor, rather than re-using cached pages. Based on how personalized the site is, you should be able to estimate the effect on the overall performance of the platform.
Jahia uses a “per fragment” approach, meaning that personalizing only a subsection of a page will only force Jahia to put an extra effort for that section. The rest of the page can be served from the cache and deliver great performances.
Performance of a server doesn’t scale linearly.
Performance doesn’t scale linearly. This means that an average resource usage of 30% (CPU consumption) with 1000 simultaneous users won’t be 60% with 2000 simultaneous users.
Due to a lot of factors, including the time the server spends switching between concurrent user requests and the increase of the average number of tasks the server is processing at once, resource consumption is going to increase faster than the number of users added to the platform.
Hence, an average CPU usage of 50% is to be considered a high value, and not a server running at half capacity. Same thing goes for the database load and general I/O usage.
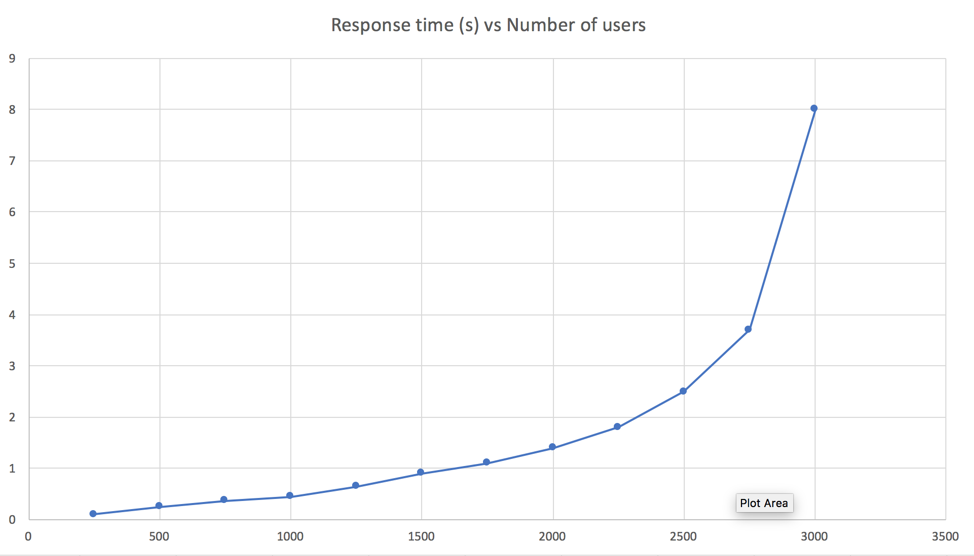
This curve is made out of virtual data* but shows the usual behaviour of a platform under increasing load. Doubling the number of simultaneous users won’t increase the response time or the CPU consumption proportionally since performance doesn’t scale linearly.
* This is an expected behaviour for most Java applications and relational databases due to concurrent locking strategies, thread context switching, concurrent memory access, file system scaling (also not linear)…
Authoring vs Browsing nodes
Authoring and Browsing activities are to be separated since they don’t scale the same way.
Contribution activity usually allows for a few hundreds contributors using the platform at the same time. (Jahia’s internal performance tests simulates 600 simultaneous content creators). Contribution can scale beyond the 600 users mark but this is a requirement that has never been expressed by our clients so far, hence, it is not part of our automated tests. For any requirements needing a highly scalable contribution architecture, please reach out to a Jahia architect.
The browsing activity scales way higher with a virtually unlimited number of browsing servers that can be added to the architecture. Only real-life performance tests will be able to provide the number of browsing nodes necessary for a given architecture.
Maximum response time?
Response time is part of the SLA of a platform. It is absolutely vital to define it before deciding on the size of an architecture. Response time usually increases with the load on the platform, hence an architecture with very short allowed response time will usually necessitate more servers to respond quickly.
Response time for a page is usually defined in milliseconds (ms) and can be measured in two different ways:
- Page generation time on the server
- Page load time on the user browser
It is important to define which way of measuring is actually used since they are likely to be different from each others. Jahia is only responsible for the time it takes to generate a page and send it back to the web server or the load balancer. Other durations added by networks, firewalls, browsers parsing HTML DOM and Javascript execution are relevant to the user experience, but aren’t managed by Jahia.
Number of concurrent visitors?
Concurrent visitor number is usually not the figure we are looking for when defining the size of an architecture. The most useful figure is the TPS (Transaction Per Second). It is the number of user requests reaching the server each second. It gives a very good estimate of the load of a server.
It is often hard to derive the number of TPS from the number of users connected to a site, unless the behavior of the users is well known. Data such as the think time (average duration between two actions) can help reach a good approximation of the TPS.
2000 concurrent users with a think time of 45s gives 2000/45 = 60 TPS.
The best way to know the TPS of an existing platform is usually to part its logs and count the number of incoming requests.
Static assets served from a cache or a CDN
Jahia can be used to generate dynamic pages and serve static assets such as pictures, documents, javascript and css files. While generating dynamic content is probably the best use of Jahia, serving static assets can sometimes be offloaded to an external service.
Local caches such as some Apache plugins or Varnish cache can be used while CDNs allow for a global distribution of the assets worldwide. These features greatly help reduce the overhead of Jahia. These caches can only be used for public facing documents, since Jahia’s permissions and roles won’t be checked when serving static files from an external cache.
Size of the content
More content not only means more disk usage, but also more resource usage while displaying it. After being displayed in a page, Jahia content is usually cached and served from the cache the next times. More content means more different items to generate and more entries in the cache.
Acceptable server failure
Server failure happens to every architecture, these downtimes needs to be included in the global capacity of a platform. An architecture working at full capacity with a given number of servers won’t sustain the load if one server fails.
Jahia nodes are only a part of the overall architecture. Database, shared file system failover, front-end web server and load balancer failover also need to be anticipated in order to guarantee a reliable service.
The Service Level Agreement needs to provide the acceptable number of server failure allowed while coping with the traffic. The default choice is to add one browsing Jahia server to the minimum architecture, but more demanding or mission critical services might require more.
Quality of the code
Code quality generally makes a huge difference on the scalability of a platform. Limiting backend calls, leveraging the built-in caches and creating specific ones is usually a key aspects of the scalability of a platform.
Jahia developers are offered a great flexibility with powerful querying and displaying capabilities. With great power comes great responsibility.
How to decide on the size of an architecture
Here is a list of important questions when discussing the size of a Jahia architecture:
- How many concurrent users are expected on the site during traffic spikes?
- How many Requests per Seconds (or TPS) are expected during traffic spikes?
- What is the expected traffic growth within one year? three years?
- When is the traffic spike usually happening?
- Is the site providing an authentified section?
- If yes, how many users have user accounts?
- Is the site displayed the same for all visitors, or is it personalized?
- How many pages exist in the site?
- Are static assets cached in anyway? (Apache/Varnish/nginx/CDNs…)
- What is the expected response time for a page? (average in millisecond)
- What is the expected response time for a page? (maximum in millisecond)
Other considerations
Jahia can be used to host hundreds of sites. While the technical scalability of the platform has to be taken into account, other factors also come into play.
Different SLAs on the same architecture
Different sites usually means different teams and different SLAs. While sites are usually independent from each others on a given cluster, maintenance operations performed on that cluster can have a global effect. Servers restart and maintenance are likely to impact all sites and will need to be scheduled with all the stakeholders.
Sites with very high availability requirements (>99.9%) are usually better off being hosted on a dedicated architecture in order to mitigate the number of operations due to other teams.
Code sharing
Different sites are likely to share some or all the code base. Shared features will also need to be upgraded all at once since the same version of the code (modules) will need to be deployed at once on a given architecture. Requirement of deploying new features at different time usually requires splitting the architecture to allow for different code base deployed on different sites.

Content sharing
Sharing content usually means sharing the same cluster amongst different sites. If this solution is not possible, some alternatives exist, such as the External Data Provider.